Clúster servidor de archivos

En una entrada anterior se vio como crear un servidor de archivos donde los usuarios pueden almacenar de forma centralizada sus documentos. El hecho de hacerlo de esta forma proporciona muchas ventajas en el entorno: el usuario puede cambiar de dispositivo sin perder el acceso a los ficheros, el administrador de sistemas puede controlar correctamente el acceso a los mismos estableciendo los niveles de seguridad necesarios, controlar el espacio físico que ocupan los datos, hacer copias de seguridad, etc…
¿Pero que pasa cuando este servidor deja de dar servicio?
Ya sea porque hay que hacer las actualizaciones correspondientes, mantenimiento del hardware que lo soporta, ampliaciones, un problema cualquiera que deja el servidor frito, etc. Pues, que los usuarios dejan de tener acceso a sus documentos y ya la hemos armado.
Cada vez más muchos servicios de TI se convierten en vitales para el funcionamiento de la empresa. Las empresas también han cambiado, han pasado de un modelo donde encontrábamos ventanas de tiempo para poder hacer las tareas de mantenimiento, a un modelo donde estas ventanas cada vez son menos. Usuarios que se conectan desde casa al atardecer, noche o fin de semana; delegaciones en la otra punta del mundo con husos horarios diferentes, entorno de producción 24×7 que se ha integrado en la red informática, etc… Y no hablo de las grandes empresas (que ya lo tienen), si no también de las PYMES, que cada vez más adoptan (o tienen que adoptar) este modelo.
Frente a este reto empresarial, nuestros departamentos de TI tienen que dar una respuesta firme, que permita dormir tranquilos, sin trabajar a deshoras y corriendo, pudiendo hacer las tareas de almacenamiento tranquilos y sin que aparezca la tan temible gota de sudor frío.
Como lo hacemos?
Buscando la alta disponibilidad del servicio crítico. Es decir, un sistema que me permita apagar uno de los servidores que ofrece el servicio sin que eso suponga la pérdida del mismo.
Anteriormente se conseguía mediante dos servidores y un almacenamiento compartido entre ellos, muchas veces una solución cara al alcance de pocos. Uno de los servidores es el que ofrece el servicio, el otro está a la expectativa de si cae el primero. Eran montajes muy habituales en bases de datos, archivos o servidores de correo electrónico. En caso de caída del primero (ya sea por mantenimiento o por un error del mismo), el segundo coge la batuta del servicio.
Debido a la evolución tecnológica, actualmente, algunos servicios han mejorado esta disponibilidad incorporando métodos propios. Por ejemplo, Microsoft Exchange y Microsoft SQL Server utilizan una tecnología de bases de datos en alta disponibilidad, donde aparte del servidor, el servicio también se encarga de copiar los datos en ficheros diferentes asegurando la consistencia de los mismos (ya no se dispone de un servicio de almacenamiento compartido). Pero continúan existiendo una serie de servicios (servidor de archivos, DHCP, Hyper-V, …) en que hay que asegurar su disponibilidad que por la tipología del servicio no requieren de las otras tecnologías que he comentado. Para ellos, continúa existiendo el clúster de conmutación por error.
Los costes en hardware, licencias y la virtualización también han ayudado a hacer más accesibles estas tecnologías para la gran mayoría, pudiéndose aplicar de forma habitual.
Clúster de conmutación por error del servidor de Archivos
Después de todo este «rollo» introductorio vamos al grano con la configuración. Partimos de dos servidores virtuales (srvFS01 y srvFS02) con Microsoft Windows 2012 R2. Los dos servidores tienen dos tarjetas de red (una para la red empresarial y la otra para conectarse a un volumen compartido iSCSI). En el ejemplo, crearemos un «servidor de archivos en la red» (srvFS) que compartirá la carpeta Departamentos ubicada en el volumen iSCSI. El objetivo es poder parar el servidor srvFS01, que originalmente es el servidor ACTIVO, pasando el rol al servidor srvFS02; sin que los usuarios pierdan el acceso a sus datos y al revés. Por tanto, el servicio tiene que pasar de un servidor al otro.
El diagrama muestra la configuración a grandes rasgos.

Preparativos para montar el clúster
Conexiones de red
Los servidores disponen de dos tarjetas de red (Ethernet0 y iSCSI), por lo tanto, hay que asegurarse que la tarjeta que aparece en el panel de control se corresponde a la tarjeta física (uno de los trucos que siempre funciona es desconectar el cable para ver quien pierde el enlace). Es decir, hay que comprobar que la conexión física se corresponde con la lógica (tarjeta de red del panel de control), sino cuando se asignen las direcciones IP podemos sufrir. También hay que asegurar que los servicios del servidor se inicien con la tarjeta que corresponde a la red (Ethernet0) donde habrá los usuarios y no a las secundarias (iSCSI).
¡Estos son algunos de los principales errores en los montajes con múltiples tarjetas!
Para asegurarlo, hay que ir al Panel de control > Centro de redes y recursos compartidos. En el menú de la izquierda, seleccionar Cambiar configuración del adaptador.

En la nueva ventana que contiene las dos tarjetas de red, pulsar la tecla ALT para hacer aparecer el menú. Seleccionar Opciones avanzadas > Configuración avanzada.

En la pestaña Adaptadores y enlaces, comprobar que el orden de las conexiones sea el adecuado.

Comprobado el orden de inicio de las tarjetas de red en los dos servidores y las correspondencias de las mismas, se pueden asignar las direcciones IPs correspondientes:
- srvFS01 Ethernet0: 192.168.1.21 iSCSI: 192.168.100.21
- srvFS02 Ethernet0: 192.168.1.22 iSCSI: 192.168.100.22
En la tarjeta iSCSI, desactivaremos todos los servicios menos:
- Programador de paquetes QoS
- Protocolo de Internet versión 4 (TCP/IPv4)

Además, en las propiedades de esta última interfaz, no se configuraran los servidores DNS.

Hacer clic en el botón Opciones avanzadas, pestaña DNS, también se desmarca la opción de Registrar en DNS las direcciones de esta conexión. Ya que no se quiere ofrecer servicios para esta tarjeta más allá de la conexión con el volumen iSCSI.

Discos duros
Como que el montaje consiste en un clúster de dos servidores y la tecnología de Microsoft requiere tres nodos, para el tercer nodo se utilizará un volumen de datos (el que antes era el Quorum y que ahora pasa a llamarse Witness). Por lo tanto, los dos servidores deben tener visible un disco duro de 1 GB – Witness y otro de 5 GB – Data (naturalmente en producción tiene que ser más grande).

Agregar rol de clúster
Desde el administrador del servidor > Panel, hacer clic en Agregar roles y características.

Marcar Instalación basada en características y roles, hacer clic en Siguiente.
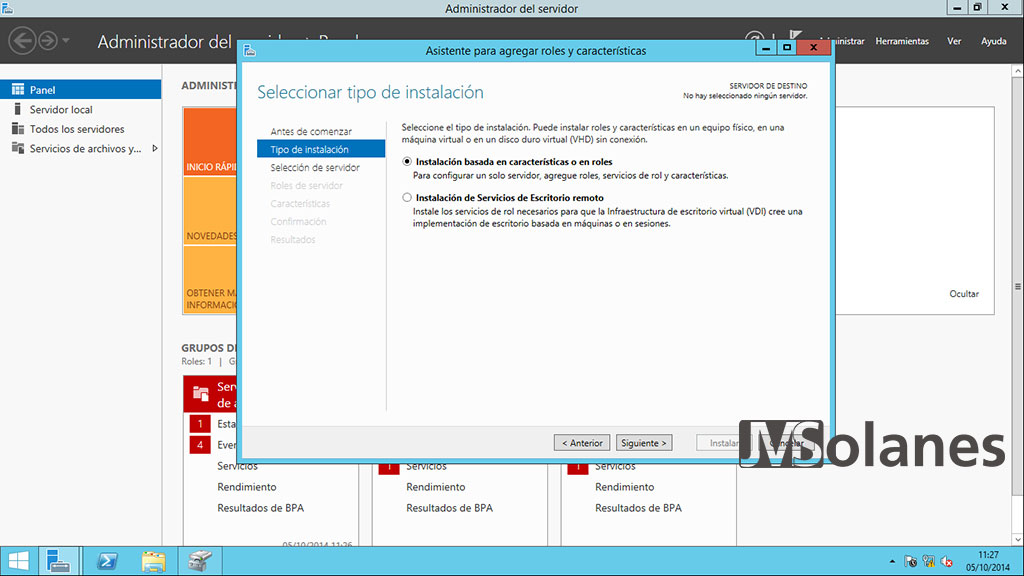
Marcar Seleccionar un servidor del grupo de servidores, indicar el servidor donde instalar la característica. Al final se tiene que haber hecho a los dos o más servidores que tienen que formar el clúster. Hacer clic en Siguiente.

Saltar el apartado de roles, ya que se quiere añadir una característica. Hacer clic en Siguiente.

Marcar Clúster de conmutación por error. Aceptar la sugerencia de añadir las herramientas de administración. Hacer clic en Siguiente.

Resumen de lo que hay que instalar. Hacer clic en Instalar y esperar a que el servidor trabaje para nosotros.

Una vez instalado ya se puede cerrar el asistente. Hacer clic en Cerrar y reiniciar el servidor.
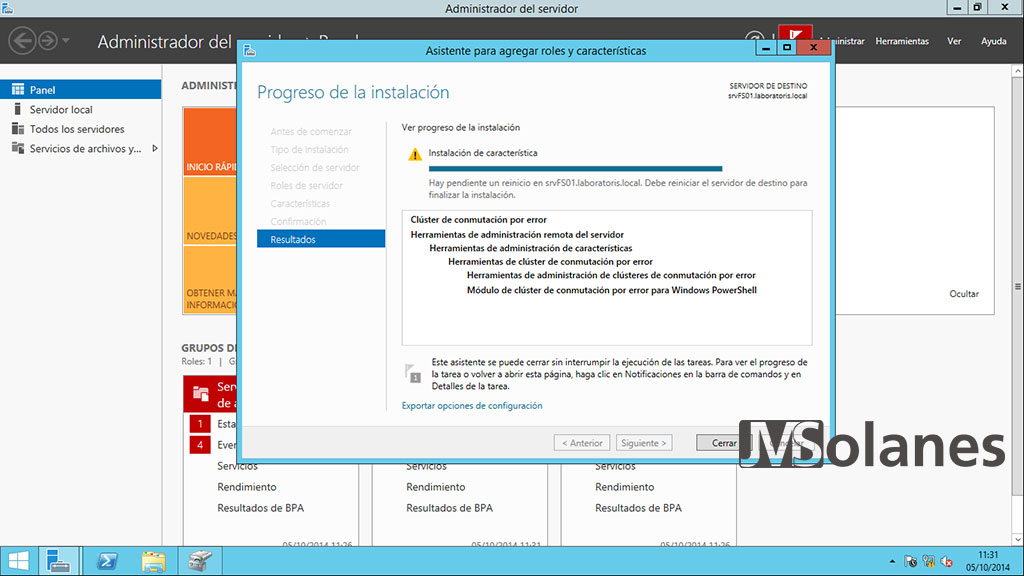
Repetir las mismas operaciones para el resto de servidores que tienen que formar el clúster.
Creando el clúster
Iniciado el/los servidor/es de nuevo, en las herramientas administrativas tiene que aparecer la consola de configuración y control del clúster de conmutació por error. Desde el Administrador del servidor, menú Herramientas > Administrador de clústeres de conmutación por error.
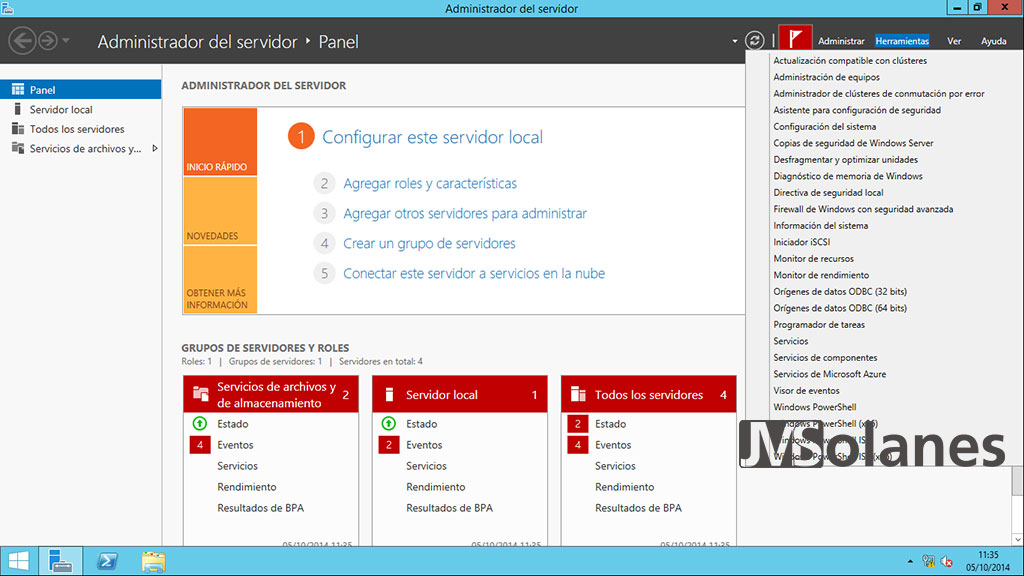
Con la consola de administración abierta, toca comprobar que todo sea correcto. En el lado izquierdo, seleccionar Administrador de clústeres de conmutación por error > botón derecho del ratón > Validar configuración.

Se inicia un asistente para hacer la validación. Hacer clic en Siguiente.

Indicar los servidores que tienen que formar parte del clúster, pulsando el botón Examinar y indicando el nombre de los equipos.

El servicio valida los nombres (y cuentas de equipo) de los dos servidores y los añade a la lista de nodos. Hacer Clic en Siguiente.

Permite escoger si se hacen todas las pruebas o se quiere seleccionar cuáles se tienen que llevar a cabo. Al ser una configuración inicial es muy recomendable que se hagan todas las pruebas.
En caso de estar en producción y querer validar la configuración, alerta con los discos duros ya que las pruebas con ellos puede dejar sin servicio. Hacer clic en Siguiente.

Resumen de lo que se debe comprobar. Hacer clic en Siguiente para iniciar las pruebas.
Esperar un rato a que se hagan las pruebas.

Una vez se han terminado las pruebas de validación, se le puede dar un vistazo al informe. Si se produce un Error no nos dejará crear el clúster. Si se produce una Advertencia, hay que averiguar si podemos prescindir de ella o no. Hacer clic en Ver informe…

En mi caso, hay una advertencia en la red, comprobando el detalle indica un problema de comunicación entre servidores por la red iSCSI. Sabemos que no es el objetivo que haya tráfico de datos del clúster por esta red, solo debe haber el tráfico del almacenamiento, por tanto, ya es correcto que deshabilite el acceso.

Cerrar el informe y también ya se puede cerrar la ventana de validación del clúster. Hacer clic en Finalizar.

Como que el informe era correcto, automáticamente se inicia el asistente para crear un nuevo clúster. Hacer clic en Siguiente.

Nos pide el nombre del clúster (¡¡¡OJO!!! nombre del clúster, no del servicio). Le podemos poner cualquier nombre que no esté ya dado de alta en la red. Por ejemplo: cluster.

Seleccionar la red por la que será visible el servicio: 192.168.1.0/24 y asignar la dirección IP del servicio de clúster (que no la del servicio de archivos) haciendo clic en la columna de Dirección. En mi caso, 192.168.1.20.
Deshabilitar la otra red. Hacer clic en Siguiente.
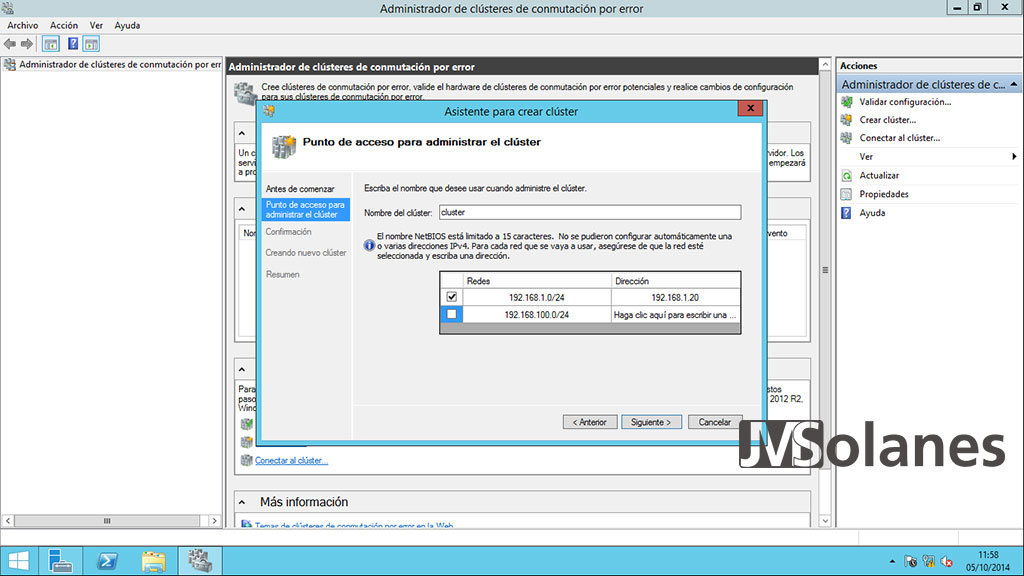
Resumen de la configuración. Ojo con el checkbox de «Agregar todo el almacenamiento apto al clúster«, si lo dejamos marcado ya nos dará de alta los discos dentro del clúster, sino lo tendremos que hacer después manualmente. Hacer clic en Siguiente.

Voilà. Ya tenemos el clúster creado. Hacer clic en Ver informe para revisar las acciones o bien Finalizar.

Lo que nos queda ahora es la consola de administración del clúster, visualizando el clúster que acabamos de crear (valga la redundancia). Pero es un clúster vacío, no tiene servicios, no tiene contenido. Repasemos su configuración.

Configuración del tercer nodo del clúster en Quórum (Witness)
Botón derecho encima del nombre del clúster, en el menú, seleccionar Acciones adicionales > Configurar opciones de quórum de clúster.

Se inicia un asistente. Hacer clic en Siguiente.

Permite indicar el tipo de configuración del quòrum (Witness en inglés). Seleccionar Configuración de quórum avanzada. Hacer clic en Siguiente.
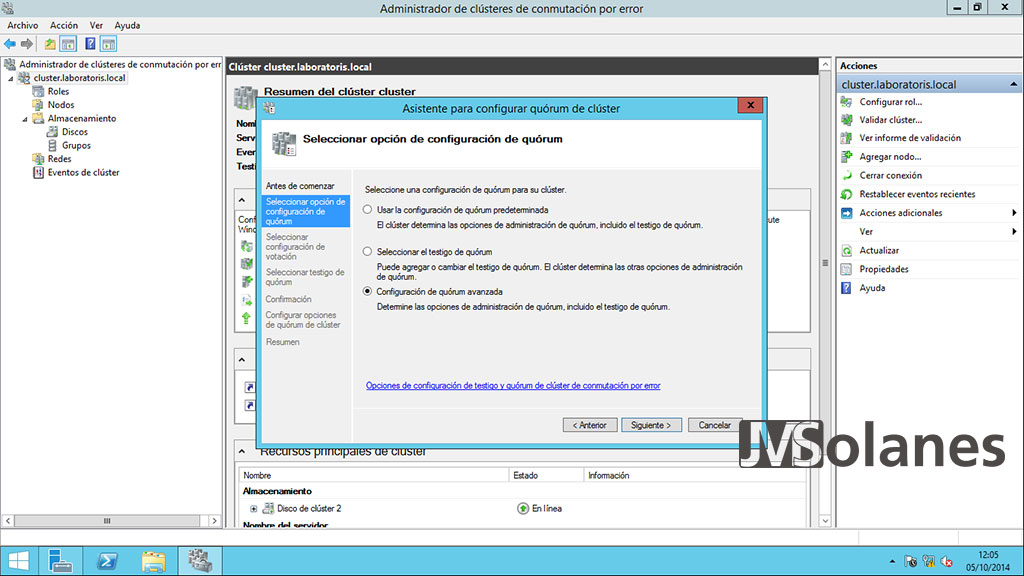
Seleccionar los nodos que deben poder votar. Mejor dejarlos todos, de esta forma si cae cualquiera de los nodos no por eso dejará de funcionar el clúster. Marcar Todos los nodos y hacer clic en Siguiente.

Como que no tenemos suficientes nodos (necesitamos mínimo 3), el tercero tiene que estar basado en el disco. Seleccionar Configurar un testigo de disco y hacer clic en Siguiente.
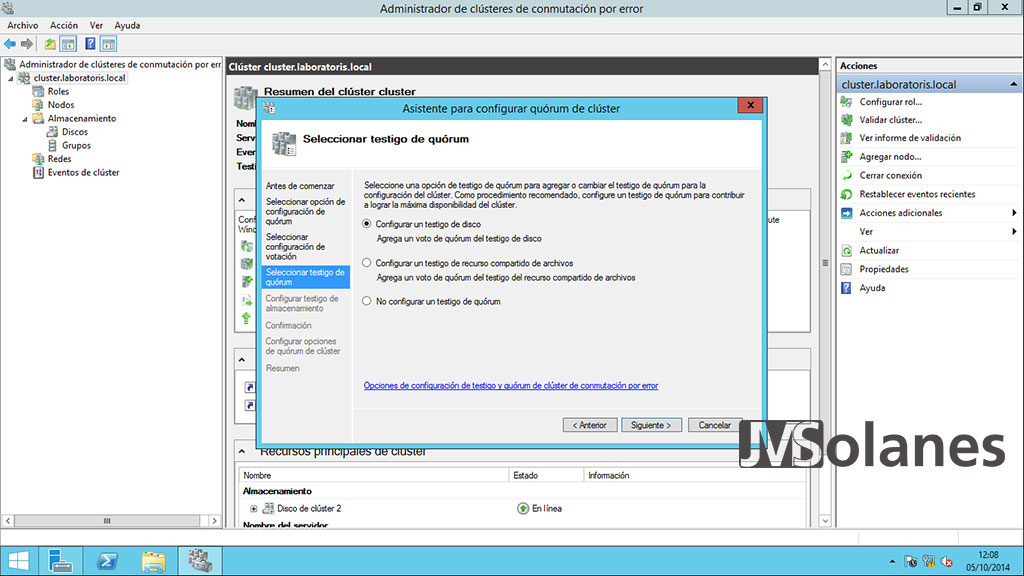
Indicar el volumen que se utilizará para el quòrum, el disco de 1 GB. Seleccionarlo y hacer clic en Siguiente.

Todo a punto para establecer el tercer nodo. Hacer clic en Siguiente.

Ya lo tenemos operativo. Hacer clic en Finalizar.

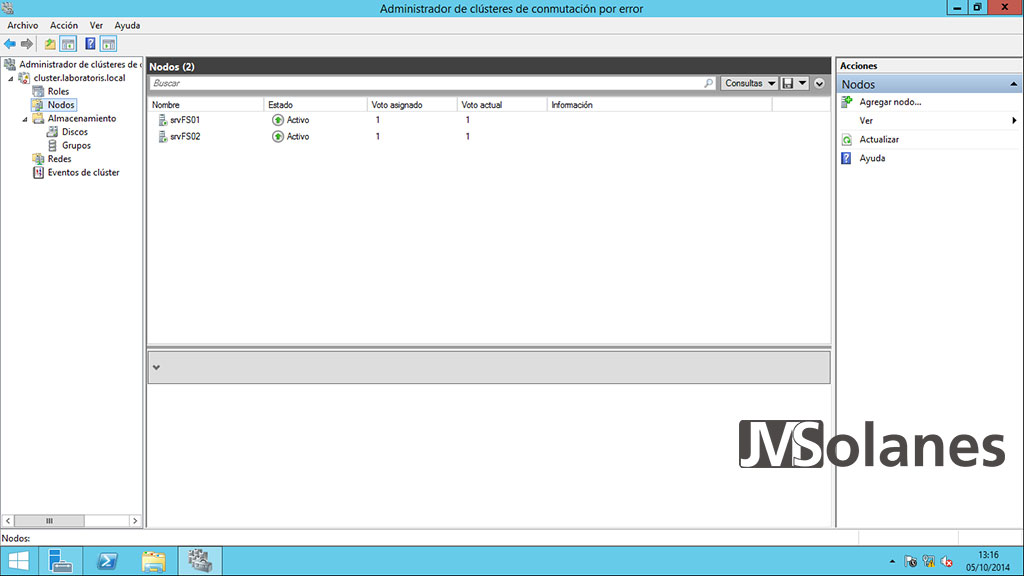
Los nodos del clúster
En la carpeta Nodos tenemos información de los servidores que pertenecen al clúster y su estado. Pulsando encima del servidor con el botón derecho, se puede parar o arrancar el servicio de clúster en el nodo, expulsar el nodo del clúster o ver los eventos críticos del mismo.

Almacenamiento perteneciente al clúster
En la carpeta Almacenamiento > Discos se encuentran los discos disponibles dentro del clúster y la función que tienen.

En el caso que el disco que queremos utilizar no esté, se tiene que dar de alta mediante la opción Agregar disco del menú de la derecha o haciendo clic con el botón derecho del ratón encima de Discos > opción Agregar disco.
Para añadir un disco al clúster, éste debe estar previamente formateado

Desde este apartado también se puede mover el almacenamiento de servidor activo, con la opción Mover almacenamiento disponible…
Redes del clúster
Como indica su nombre, las redes que pertenecen al clúster y los servicios que por ellas corren. En el ejemplo que seguimos, la red 1 (Ethernet0) se utiliza para el clúster y los clientes y la red 2 (iSCSI) no tiene ninguna utilidad a nivel de clúster. En un entorno productivo no es demasiado aconsejable que haya el servicio de clúster mezclado con la red de clientes (a no ser que se trabaje con sistemas de redundancia a nivel de red como el 802.1ad), por lo que la red 1 tendría los clientes y la red 2 el clúster. Para mejor comprensión del administrador, yendo a las propiedades de la red se le puede cambiar el nombre.



Para comprobar que el servicio de clúster está levantado y operativo, desde un equipo cliente, se puede acceder vía red al nombre que se ha creado (\\cluster.laboratoris.local). No tiene que aparecer con ninguna carpeta compartida, ya que el servicio está vacío.

Servicio de Archivos en un clúster
Desde el administrador del clúster de conmutación por error, seleccionar la carpeta Roles, botón derecho y hacer clic en Configurar rol.

Se inicia un asistente para dar de alta nuevos servicios en configuración de alta disponibilidad. De la lista, seleccionar Servidor de archivos y hacer clic en Siguiente.

Seleccionar el tipo de servidor de archivos:
- Archivos para uso en general. Adecuado para las carpetas departamentales y de usuarios.
- Archivos de escalabilidad. Para alojar máquinas virtuales o bases de datos en red.
Seleccionar para uso en general y hacer clic en Siguiente.

Indicar el nombre por el servidor del clúster de archivos. Aquí si que debemos de poner el nombre por el que queremos que los usuarios accedan a las carpetas (o no, si hay un DFS). También hay que especificar la IP de este servicio.
- Nombre: srvFS
- IP: 192.168.1.23
Hacer clic en Siguiente.

El servicio tiene que guardar los archivos en algún sitio, seleccionar el disco duro que tenemos disponible al servicio de clúster. Hacer clic en Siguiente.

Resumen de la configuración del clúster. Si todo es correcto continuamos adelante, hacer clic en Siguiente.

Se ha acabado, se puede revisar el informe o cerrar el asistente. Hacer clic en Finalizar.

Volviendo a la consola de administración del clúster de conmutación por error, seleccionar la carpeta roles para comprobar que se ha creado y iniciado el clúster de archivos.

Desde otro equipo de la red también podemos comprobar que es accesible \\srvfs.laboratoris.local, pero tampoco está sirviendo nada de nada.

Volviendo al administrador del clúster de conmutación por error, la carpeta roles, botón derecho encima del servidor de archivos, se pueden compartir las carpetas: Agregar recurso compartido de archivos.

Se inicia un asistente para crear la carpeta compartida con 5 opciones:
- SMB – Rápido. Viva los asistentes, luego podremos acabar de retocar según nuestros intereses y no los de la máquina.
- SMB – Avanzado. Permite personalizar la carpeta, se requiere que antes haya instalado el rol de Administración de recursos del servidor de archivos.
- SMB – Aplicaciones. Aplicable cuando se comportan carpetas para Hyper-V, por ejemplo.
- NFS – Rápido. El mismo que el SMB, pero para protocolo NFS (Linux).
- NFS – Avanzado. El mismo que el SMB, pero para protocolo NFS (Linux).
Seleccionar SMB – Rápido y hacer clic en Siguiente.
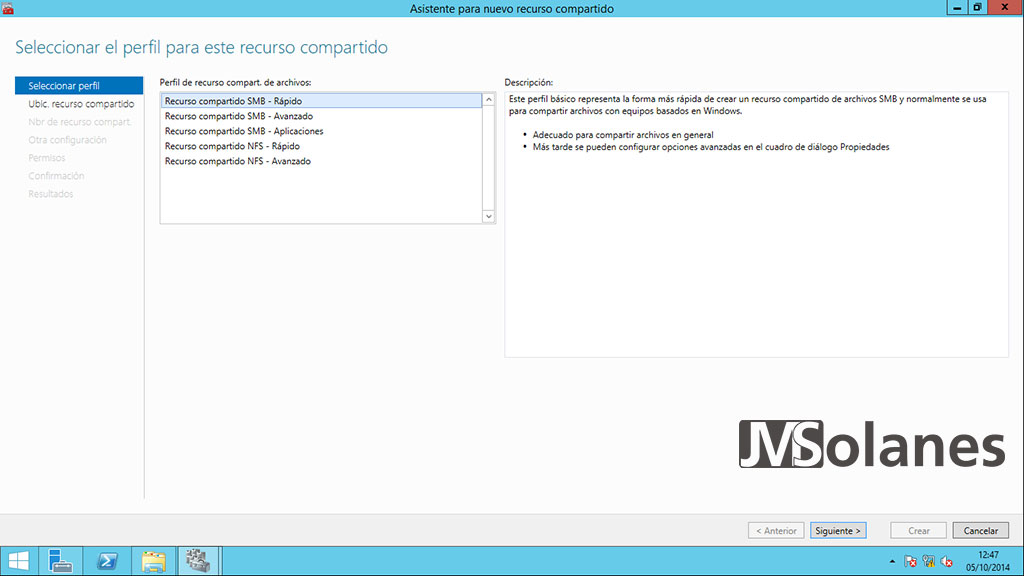
Seleccionar el servidor (del clúster), el volumen donde alojar la carpeta compartida (en este caso la L:) y hacer clic en Siguiente.

Indicar el nombre del recurso compartido: Departaments. Observar que el sistema creará la carpeta física en la L:\Shares\Departaments. Hacer clic en Siguiente.

Opciones de configuración del recurso compartido:
- Habilitar enumeración basada en el acceso. «Ojos que no ven, corazón que no siente«. Altamente recomendado en entornos departamentales. Si el usuario no tiene permiso para acceder a una carpeta, el sistema ya no la muestra.
- Habilitar disponibilidad continua. Estamos configurando un clúster de alta disponibilidad, lo que precisamente queremos es que si uno de los servidores cae, la recuperación del servicio sea lo más rápido posible. Marcando esta opción acelera la caída reduciendo este tiempo. Vaya, que el usuario no se da cuenta que ha caído un servidor.
- Permitir almacenamiento en caché del recurso compartido. La misma recomendación que si no estuviera en clúster, personalmente NO me gusta dejar esta opción en carpetas departamentales o compartidas por múltiples usuarios ya que se puede formar un caos con las versiones. Solo para las carpetas particulares de cada usuario.
- Cifrar acceso a datos. Como su nombre indica permite cifrar los datos en tránsito.
Cuando lo tengamos a nuestro gusto, hacer clic en Siguiente.

Permisos. Aquí no hay demasiado más que decir, según lo que convenga en cada carpeta. Hacer clic en Siguiente.
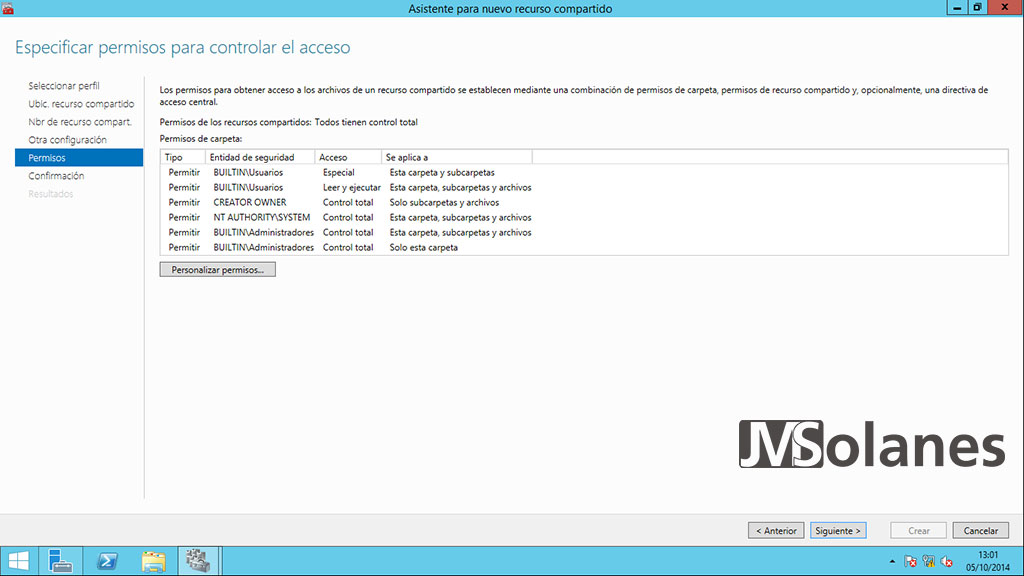
Resumen de lo que se debe hacer. Hacer clic en Crear.

Y ya está. Hacer clic en Cerrar.

Volver a comprobar desde un equipo de la red que ahora sí ya se comparte la carpeta Departaments. \\srvfs.laboratoris.local.

Repetir el proceso para crear el resto de carpetas necesarias.
Para personalizar los permisos de la carpeta, podemos acceder con el explorador de Windows a la carpeta y trabajarlo como si no fuera parte de un clúster.
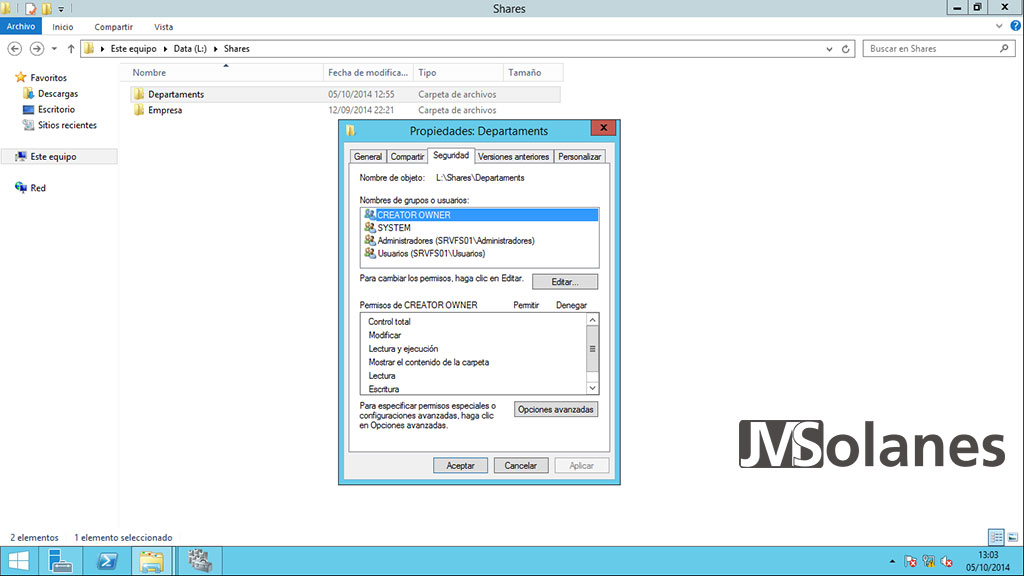
Comprobando el clúster
¿Todo esto es muy bonito, pero funciona?
Antes de entrar en producción, hay que comprobar que todo esté correcto y funciona como esperamos. ¿La mejor manera? hacer caer el nodo que tiene el servicio. Se puede hacer de:
- forma ordenada. En los casos de mantenimiento del servidor, donde el administrador mueve el servicio o apaga controladamente el nodo activo desde el administrador de clústers.
- forma «bruta». Apagar directamente el servidor que controla el servicio por el botón.

Desde un equipo copiamos el contenido de una carpeta a la carpeta del clúster.

Apagamos el nodo activo a saco, la copia se queda un rato parada, pero no hay errores, esperamos.
Pero al cabo de unos segundos continúa copiando! (ha pasado demasiado rápido para poder hacer la captura).
Abriendo el administrador del clúster en el otro servidor, se observa que el servicio ha pasado a ser activo en el segundo servidor

Y que el primer servidor está apagado o fuera del clúster.

Pero el servicio de archivos continúa funcionando.
Recuperamos el primer servidor poniéndolo en marcha.
Pero por el hecho de arrancarlo, no se traspasa el servicio de un servidor a otro; continúa en el servidor srvFS02.

Traspasamos de forma ordenada el servicio de un nodo a otro, mientras está copiando claro. Botón derecho sobre del servicio, Mover > Mejor nodo posible.

Hecho. El servicio ha pasado al primer servidor srvFS01.

La copia ha tenido una pequeña penalización (pausa) casi inapreciable, mucho menos que en el caso anterior.

Afinando la caída del clúster
Hay que tener en cuenta las propiedades de error y caída del clúster, ya que por defecto solo permite la caída de un nodo en un período de 6 horas. En caso que hubieran más caídas el servicio dejaría de funcionar. Por lo tanto, es importante configurar estas características.
Desde el Administrador de clústers, carpeta Roles, seleccionar el rol en cuestión, botón derecho, Propiedades.

La primera pestaña, General, permite definir quien es el servidor predilecto del rol; si tiene que haber.

La segunda pestaña, Conmutación por error, permite el número de errores admitidos dentro de un período de tiempo. Así como la recuperación del servicio. Os acordáis que cuando se ha puesto en marcha el primer servidor el servicio no ha vuelto de forma automática? Pues esto es lo que controla este punto. Utilizar según las necesidades.

Y hasta aquí este artículo que ha salido muy largo y concentrado. Si te ha gustado, lo puedes compartir en las redes sociales. También puedes dejar tu opinión, comentario o sugerencia. ¡Gracias!
Similar Posts by The Author:
- Microsoft SQL Server con SMB3
- Microsoft SQL Server amb SMB3
- Containers en Linux
- Containers amb Linux
- Migrar el servidor de archivos a Windows Server 2019
- Migrar el servidor de fitxers a Windows Server 2019
- Puerta enlace a Azure en el Windows Admin Center
- Porta enllaç a Azure en el Windows Admin Center
- Hola mundo! WordPress 5 y Gutenberg
- Hola món! WordPress 5 i Gutenberg
No me ah funcionado, cuando válido el cluster me da un error y es que no detecta discos duros compatibles, eh creado un disco duro virtual compartido en el servidor de archivos y lo conecte con iscsi a los dos servidores y así me funciono, como lo soluciono, me parece que es mejor como lo hacen aquí, porque no depende de un solo servidor(donde cree el disco virtual), si me ppodrían ayudar, gracias.
Hola Harold, no entiendo muy bien tu comentario. Me lo podrías aclarar un poco más, por favor.
Validar de los discos en clúster quiere decir que el disco es accesible por los dos nodos a la vez, independientemente de los mismos. Los discos tienen que estar firmados y ser posible pasar de un nodo al otro para que la validación sea correcta y el clúster pueda funcionar. No sirven discos locales. Puedes revisar el vídeo montaje del clúster de Windows Server 2012R2 que tengo en el canal de YouTube por si te sirve de mejor ayuda.
Primero gracias por responder, mira yo se como montar el cluster, se tiene por ejemplo: servidor1, nodo1,nodo2, el servidor 1 tendrá el almacenamiento compartido, y se conecta por iscsi de los nodos, osea que cada nodo tendrá acceso al mismo almacenamiento y se podrá crear el cluster sin problemas, si cae un nodo el otro responde o los que coloque en el cluster, mi pregunta es como hago si el servidor1 se cae por algún daño? Quería saber como tener otro almacenamiento con la misma información y que si falla el servidor1 le sirva a los nodos y no detener el servicio, algo como lo que pasa con los nodos, si me entiendes?, te agradesco que me ayudes, no eh podido hacer eso y quiero aprenderlo, ya eh buscado por todos lados y nada, gracias.
Perdona, estos días voy un poco liado con otros proyectos. Sobre tu pregunta que no sé si está contestada o no.
Para que me situe, estas utilizando el servidor1 como cabina de almacenamiento, donde tienes todos tus datos. Como bien dices si este equipo se para o se cae deja de funcionar el invento. A nivel de tolerancia de errores tendrás configurado el RAID-1 o RAID-5, pero qué pasa cuando se apaga el equipo completamente. Pues que los datos tambien se apagan.
Para solucionar este escenario tienes el sistema Storage Space Direct (S2D para los amigos) que proporciona un entorno hiperconvergente en que generas, digamos RAIDs de almacenamiento, entre nodos. Échale un vistazo al artículo Hiperconvergencia con Storage Spaces Direct S2D/.
Saludos,
Gracias por responder, probare lo que dices.
JMSolanes, antes que nada, muchas gracias por compartir tus conocimientos, excelente tutorial muy bien explicado, muy didactico, me sirvió bastante para comprender bien el tema.
Gracias Juan Carlos.
Hola JM
Me has confundido con esto del tercer nodo. Pues sólo veo un cluster de dos nodos. Lo del tercero creo que es error de interpretación. De hecho, llegué a tu blog porque necesito crear un cluster de más de dos nodos y no sé si se requiere alguna configuración especial o sólo basta con agregar el nodo a la red iSCSI y luego agregar el tercer y cuarto nodo tal como se hizo con el primero y el segundo.
Agradeceré tus comentarios.
Saludos,
Martin
Hola Martin,
es así como comentas. Puedes ir añadiendo nodos al clúster y distribuir la carga de carpetas entre ellos si así lo consideras. Recuerda que un clúster de archivos de alta disponibilidad añades nodos para que en caso de necesidad o caída de uno, el servicio lo ofrezca automáticamente otro.
Pero que también hay clústeres de ficheros distribuidos en los que los archivos se distribuyen entre los nodos. (des de Windows Server 2012). No son tan habituales de encontrar.
Saludos,
Buenas Noches Estimado una pregunta en cuanto al apagado de un cluster. Tengo un Cluster de Ms Windows 2012 Y en el corre el servicio de SQL Server 2012 en cluster. Necesito realizar el apagado de los 2 unicos nodos que tiene. Como puedo hacer para que el cluster no intente hacer Failover una vez apagado el Nodo Pasivo. Es decir cuando vaya a apagar el Activo no se quede en un error buscando de hacer failover. Muchas Gracias.
Apagando primero los roles de clúster. No obstante, si apagas el secundario y luego el primario no tienes que tener errores ni demora en el apagado, todo se realiza de forma ordenada.
Buenas tardes Josep, Una consulta
Tengo un Failovering Cluster Windows 2008 en el cual necesito retirar del recurso de File Server varios discos (storage) que ya no se están utilizando.
Cual es la mejor practica para realizar este procedimiento de eliminación ??
Estos discos tienen tamaños de 1TB, 500GB y 600GB.
Agradezco sus comentarios
Gracias
Buenas Alexandra,
Primero debes quitar las carpetas compartidas asociadas a esos recursos. Luego, en las propiedades del servicio de ficheros del clúster, sacar la dependencia de los discos y finalmente eliminar los discos del clúster. Una vez los tengas en el sistema operativo, los pones Off-line y los despresentas de todos los nodos. Con eso no te quedará nada huérfano en el sistema.
Saludos y buena suerte.
Antes que nada, muchísimas gracias por el post. Muy útil y muy bien documentado.
Más que un comentario, tengo una consulta: una vez levantado el rol, ¿sería posible hacer que el recurso apareciera en el entorno de red, o es absolutamente necesario que los usuarios conozcan el nombre del recurso para acceder a lo que hayamos compartido en él? Quiero decir, accediendo a Red, en mi caso, aparecen los nodos, pero no el servidor con el rol de servidor de archivos creado en el cluster.
He comprobado que tanto en el AD como en los DNS el medio se ha creado, pero no se lista en la Red… ¿Alguna idea?
Hola Eduard,
El tema del entorno de red se mantiene a nivel de NetBios (una heréncia muy heréncia), con lo que debes habilitar el anuncio por WINS en las tarjetas de red y propiedades del recurso nombre del clúster. También lo puedes hacer por registro WINS con servidor WINS a tal efecto (en entornos antiguos), mapendo la unidad localmente a los equipos mediante GPO, asociando el recurso a una carpeta DFS o publicando el recurso compartido en el Active Directory.
¿Que es lo que más utilizo yo? El DFS, sin duda. Puesto en los controladores de Active Directory y creando las carpetas de acceso a los recursos de la red, los usuarios solo tienen que recordar el \\dominio.com\ y allí van a encontrar todos los datos, da igual donde esten o si se tienen que cambiar de servidor, la estructura para ellos siempre será la misma y transparente. Te animo a que lo pruebes.
Hola, tengo un pequeño problema…Dispongo de:
Una cabina de discos (tonta) hp D3700 y 2 servidores HP, en mi caso cuando conecto al cabina a uno de los servidores la detecta sin problemas y logro hacer un las configuraciones que necesito como 2 RAID 5 con 5 discos cada uno etc etc, sin embargo al abrir la configuración del Servidor 2, no ve los arreglos de cabina ni nada… no se si el problema radica en la controladora de la D3700 o que estoy haciendo alguna configuración mal en los servidores.
Si realizo un cluster entre los 2 servidores los arrays de los discos deberian de detectarlos en los 2 no? y ahi seguiria a poner el recurso en alta disponibilidad para que lo que almacene (maquinas virtuales, archivos lo que sea) este disponible en cualquier servidor en caso de que uno caiga no?
Hola Saul, por lo que veo el HP D3700 es un dispositivo DAS; esto quiere decir que es un cajón de discos para ampliar el servidor donde lo conectas, pero que no puede compartir el mismo volúmen en más de un servidor. Para un clúster debes disponer de un almacenamiento compartido tipo SAN o crear un Storage Space Direct extendido entre los dos servidores. En el caso de cabinas SAN HPE la cabina más pequeña que permite o permitia esto es la HPE MSA P2000.
Saludos,
Disculpa información adicional: la cabina está conectada por cables mini SAS HD (12GB/s) en ambos servidores. Puerto 1 de cabina servidor 1 puerto 2 servidor 2
Buenas tardes Josep,
Muy buen tutorial, gracias por compartir.
De casualidad tendrás un tutorial similar pero configurando un Clúster con recurso compartido o carpeta compartida como testigo..!! que no sea por medio de Discos.
Te lo agradecería que me lo compartieras en caso de que lo tengas.
Saludos
Hola Alfredo, si te refieres al Witness de clúster es solo cambiando la ubicación del mismo, en vez de disco, a carpeta UNC de red.
Si te refieres a poner los datos del clúster de SQL Server en una ruta UNC, no lo tengo hecho, trabajaré sobre ello.
Buenas tardes Josep como estás..!!
Muy buen tutorial gracias por compartir, todo bien explicado y muy amigable.
Me gustaría saber si tienes algún tutorial de Clúster pero con Carpeta Compartida como Testigo, que no sea por medio de iSCSI con Discos.
Estoy configurando un clúster de esta manera pero al momento de configurar el SQL para conectarlo al clúster no me funciona correctamente, creo que algún paso me debe de faltar.
Los servidores son Windows Server 2012 R2.
Saludos, gracias.
Te he contestado en la entrada anterior.
Buenas tardes Josep,
Perdón no había visto tu respuesta, si me refiero a poner los datos del clúster de SQL Server en una ruta UNC, tengo el clúster de Windows configurado y con el recurso compartido agregado, son dos nodos del clúster más el servidor donde tengo la carpeta compartida que fungirá como testigo.
No se bien como hacer para que el SQL Failover Cluster vea ese recurso compartido, intenté agregar un rol en el clúster de Windows pero me marca status failed.
Agradezco mucho tu apoyo.
Saludos.
Hola Alfredo, no entiendo la configuración del clúster en SQL Server, el testigo y las carpetas compartidas.
Si pretendes poner el testigo en la ruta UNC, esa ruta debe tener los permisos adecuados para que los equipos (repito, equipos) del clúster puedan escribir.
Si te refieres en montar el SQL Server con rutas UNC, estoy preparando artículos referente a ello. Debes asignar los permisos al usuario de la cuenta de servicio de SQL Server para que tengo control total sobre las rutas UNC.
Saludos,
Excelente artículo. te pregunto a mi los nodos y el cluster me funcionan correctamente, es cuando creo el rol de servidor archivos. cuando finalizó la instalación se queda pensando levanta el servicio y al momento sale error. que será? un saludo
Así en frío no lo sé, debes revisar los logs de eventos para ver que indica. Puede ser que no haya podido crear el nombre del clúster en el Active Directory, permisos, que la IP esté duplicada, que no esté asociada una IP o nombre correcto al servicio de archivos.
Buenos días,
Considero muy interesante tus artículos, he puesto algunos en práctica y la verdad me han ayudado. Una duda en cuanto a esta entrada: quiero tener los servidores en cluster para que en caso de caída de alguno de ellos por fallo o mantenimiento, el servicio permanezca activo, pero sigo teniendo un único punto de fallo en la SAN, de tal forma que si la caída es por corte de luz (el SAI aguanta unos 30 minutos en consumir las baterías), pasado ese tiempo, el servicio cae. Mi duda es: aprovechando que tengo otra SAN en una ubicación distinta a la SAN principal, puedo mantener los archivos sincronizados en los dos almacenamientos? de tal forma que si el nodo activo y el almacenamiento activo se quedan sin suministro eléctrico, automáticamente el servicio lo ofreczca el nodo 2 y la segunda SAN de manera transparente para los usuarios. He estado haciendo pruebas con DFS, pero no termina de convencerme, en entorno de laboratorio me ha parecido bastante lento cuando uno de los nodos cae.
Gracias de antemano
Saludos
Hola Jon
Buena observación, ahí vamos a una configuración de DR o resiliente en entorno físico.
Aclaro algunos conceptos:
El DFS no te sirve para este caso al ser un sistema de archivos DISTRIBUIDO, no un sistema resiliente a fallos.
El clúster del artículo hace referencia a tener dos nodos, uno activo y otro pasivo compartiendo el mismo almacenamiento. Los datos no son resiliente, si se cae la cabina se cae el invento.
Sobre esto último, en el caso de Microsoft, la tecnología ha ido evolucionando para tener resiliencia de los datos, duplicándolos en local, como si fuesen RAID-1 de discos. Es el caso del DAG de Microsoft Exchange o el Always On de SQL Server. Y para el servicio de archivos existe el Scale Out.
Me lo apunto para un próximo artículo ya que es una espina clavada para eliminar completamente los Guest clúster de los entornos de virtualización.
En caso de las cabinas de alta disponibilidad, conozco bien las NetApp, y esta función la consigues mediante la réplica de datos en cabina. Dependiendo el modelo, y el dinero que tengas, consigues un 0 downtime (0 pérdida de datos).
Efecivamente, esa fue la primera opción que planteamos, la de replicar LUN, pero no pudimos implementarla debido a que las dos cabinas que tenemos, pese a ser del mismo fabricante, no tienen la opción de sincronización a nivel de bloque por ser de distinta tecnología y tampoco somos una empresa muy solvente como para renovar infraestructura por este motivo.
A día de hoy, para cubrir nuestro principal motivo de caídas (cortes de luz) solo se me ocurre meter baterías adicionales a la cabina y aligerar la carga actual del SAI principal, manteniendo el servicio en cluster para poder realizar tareas de matenimiento sobre el nodo pasivo.
Gracias por tus comentarios
Hola que tal,
Muy bueno el tutorial, lo unico que tengo dudas es respecto al servidor srvFS que tiene el disco compartido iSCSI, que es un punto de fallo ya que si cae este servidor se cae todo, no asi los otros dos del cluster srvFS01 y srvFS02, que cualquiera caiga el otro seguira dando servicio.
Como se podría solucionar esto?
Muchas gracias.
Saludos